Don't Page on Transient Issues
Originally written: November 26, 2019
LightStep’s current on-call responsibilities are rotated across individuals who serve as an all encompassing front-line responder to incidents. My shift is this week and this morning I was paged for an issue with our statistics ingestion pipeline, known internally as USGS.
The page said that the error rate had exceeded 5% over the past 5 minutes. I should’ve been immediately skeptical of the alert once I saw the definition. 5 minutes? That’s a really short period of time. A single transient issue could cause error rates to spike above that threshold if we are only looking over 5 minute periods. Once I opened my computer and starting looking into it, I determined that this was exactly the case.
First I looked at a stream for the operation that the alert was monitoring.
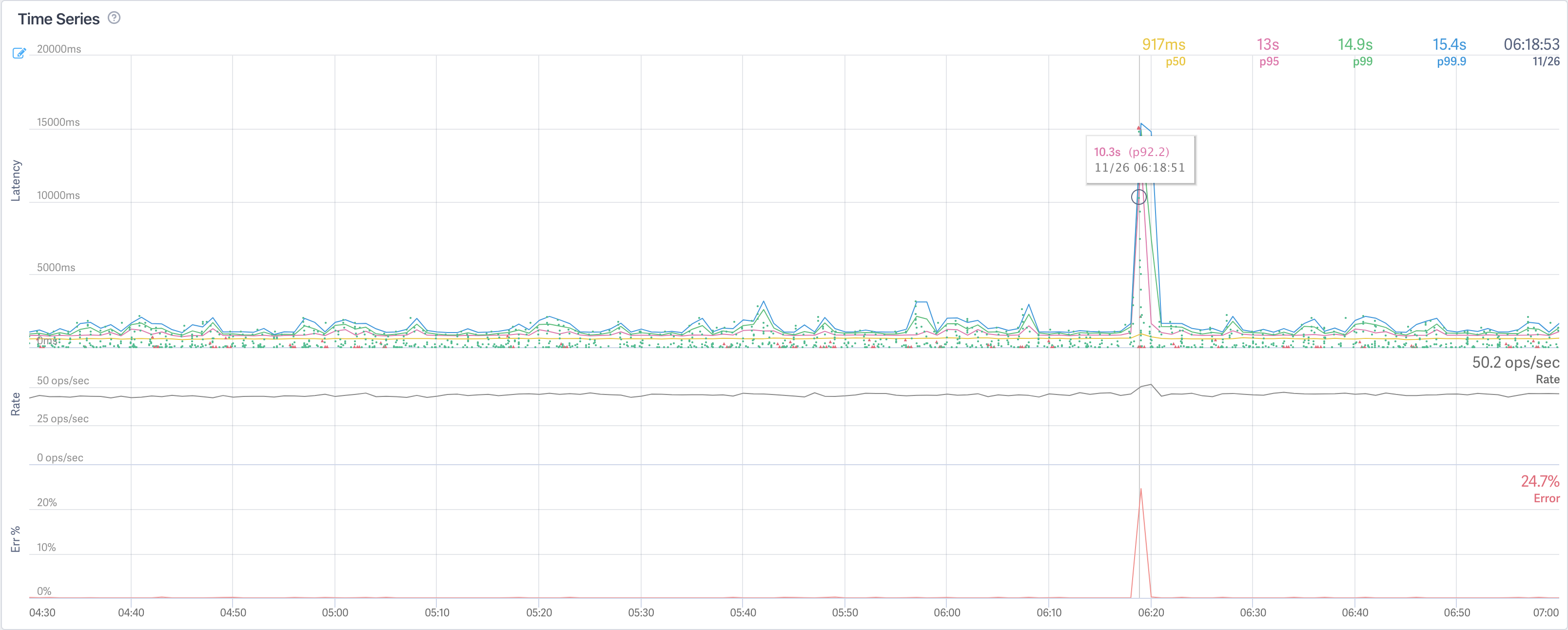
From here, I noticed that there was an upwards spike that had settled back down by the time I signed onto my computer to investigate. Clicking into a couple traces, I noticed that there were issues making calls to our service that manages database access, Bento. In order to see if this was a general Bento problem, or just a specific endpoint, I looked at a stream for the Bento service as a whole.
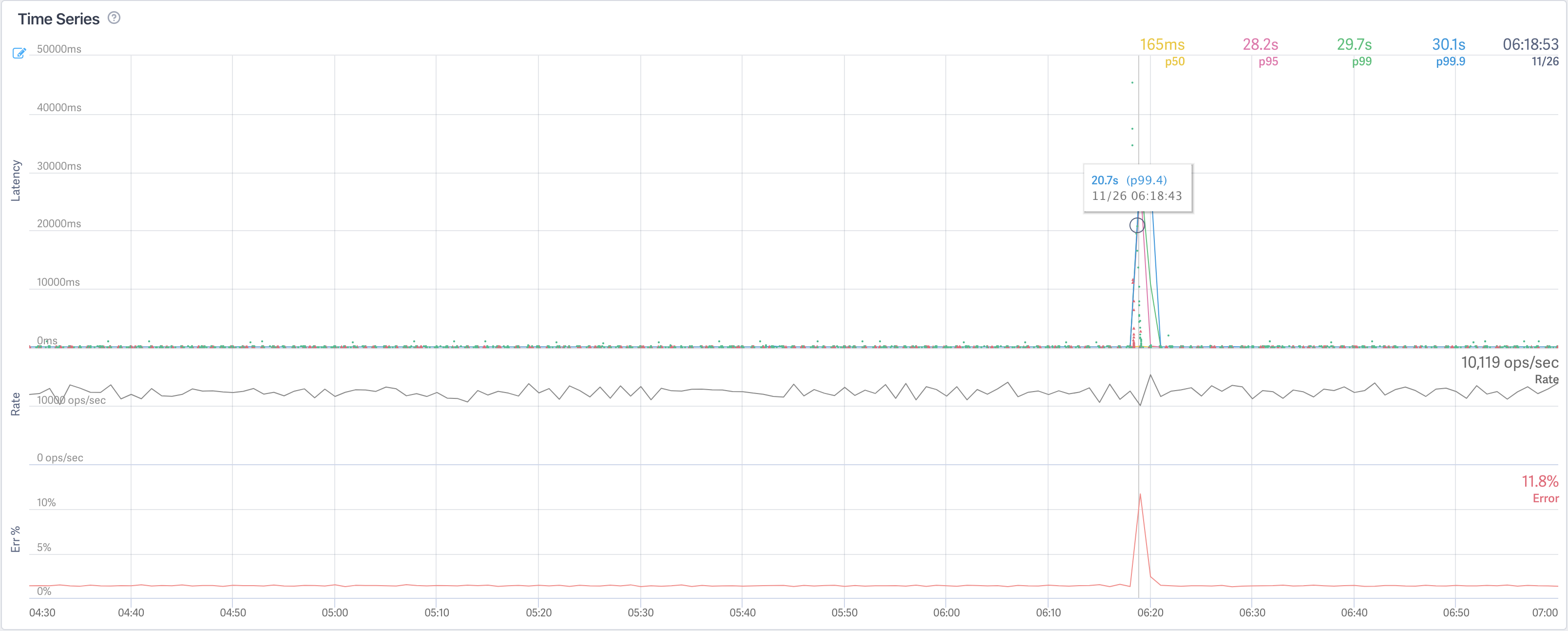
It turns out that the overall Bento service had an error spike which tightly correlated with the USGS issues. Bento doesn’t do much work, it’s mostly a wrapper around MySQL calls so I figured I should look directly at the database’s error log for more information. Sure enough, when I did so I found that the database restarted at the very beginning of the incident. This database runs in a cloud hosted environment so the next step was to file a support ticket with our cloud provider to get more information on what happened.
For this minor incident there was nothing that I, as an operator, needed to do to resolve the issue. It resolved itself. In my opinion, things that resolve themselves quickly (i.e. before a human can log on and figure out what is happening) shouldn’t page someone outside of business hours. Luckily with this incident I was already awake but it could just as easily have happened at 2am which would have left me feeling much grumpier. In order to prevent this from happening again, the alert should be made less sensitive. Ideally, it would alert when the error rate is consistently over 5% for something like 20 minutes. Unfortunately, LightStep’s alerting product doesn’t support these exact semantics (yet!), but we can approximate the behavior by increasing the error percentage threshold.